
It’s common when creating a new workflow that after the flow is finished the source data can change. The most common scenario is when connected to a database table or view and the data gets extra columns added.
In this scenario you need to make sure that your workflow doesn’t break caused by the introduction of new data.
The way to control is this through the Enforce exclusion and Enforce exclusion setting in many configuration dialogs.
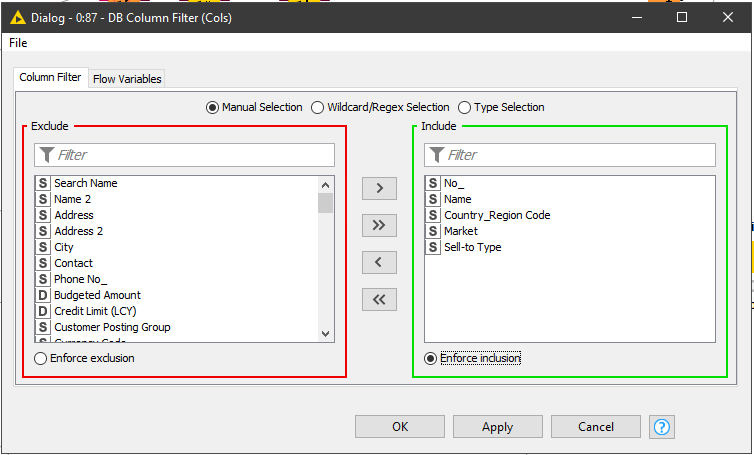
Enforce exclusion
This means that the list of fields you add to the Exclusion list will always be removed from the flow but any new columns that may appear will automatically be added to the flow in the Include list
Enforce Inclusion
This is basically the opposite. Only fields included in the Include list will be added to the flow, any new columns appearing will automatically be added to the Exclude list and remove from the flow.
Default Include or Exclude?
In general I want the data coming from a data source, whether it’s a database or a file, to be static so new fields are not automatically fed through my workflow. If I want them to propagate I’d rather control this myself. For this reason I set this to Enforce inclusion for the initial nodes directly after loading the data.
For nodes later in my workflow I do want changes to propagate, so if I make a new column it will automatically pass through to downstream nodes. Therefore I set this to the default of Enforce exclusion for all the downstream nodes after initial data load.
The KNIME default for new nodes is Enforce exclusion which in many cases is fine but just be aware what effect this will have on your flow if your data source changes to include extra fields.