Identifying Duplicate Files
Imagine you have a folder full of files, all with different names, where you need to identify which, if any, are duplicates.
You could use the file size but it’s not a guarantee the files are exactly the same just because they are the same size.
Hashing files is an easy way to identify if two files are the same as each other since even small changes in the file contents will result in a completely different hash. It also works on the file itself so the filename is irrelevant.
Current Alteryx Options
Alteryx has an md5 formula but that can only be used to calculate the hash of a field not an entire file.
The current solution is to read the file as a Blob using the blob Input tool then create an md5 hash of the blob field. While this works fine it’s very slow and you can only use md5 as the hashing algorithm.
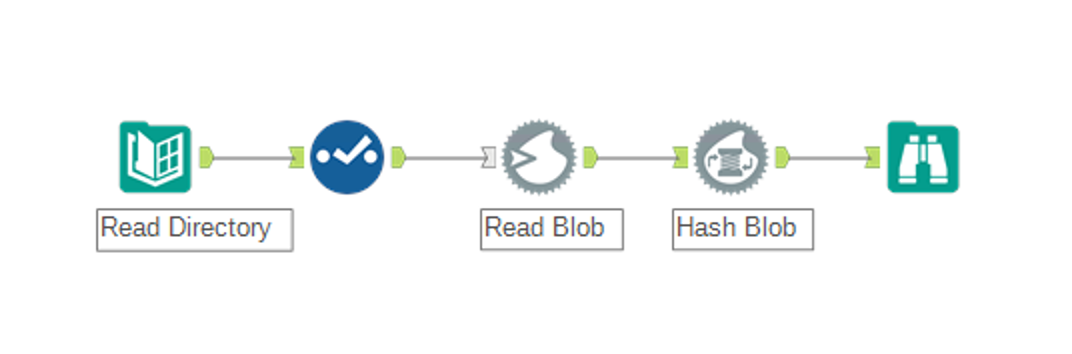
Python Macro Solution
To give more options and flexibility I’ve created a macros based on the python tool. The macros uses python’s hashlib library to do the hashing as this allows for 29 different hashing algorithms made available through the OpenSSL library.
Using the macro is simple, just feed data to the macro where one field contains the full path to the file to hash and select the hashing algorithm to use. The macro will hash the file and return all the input data while appending the hash field to the end.
File type is also irrelevant. It works equally on executables, images, binary files and so on.
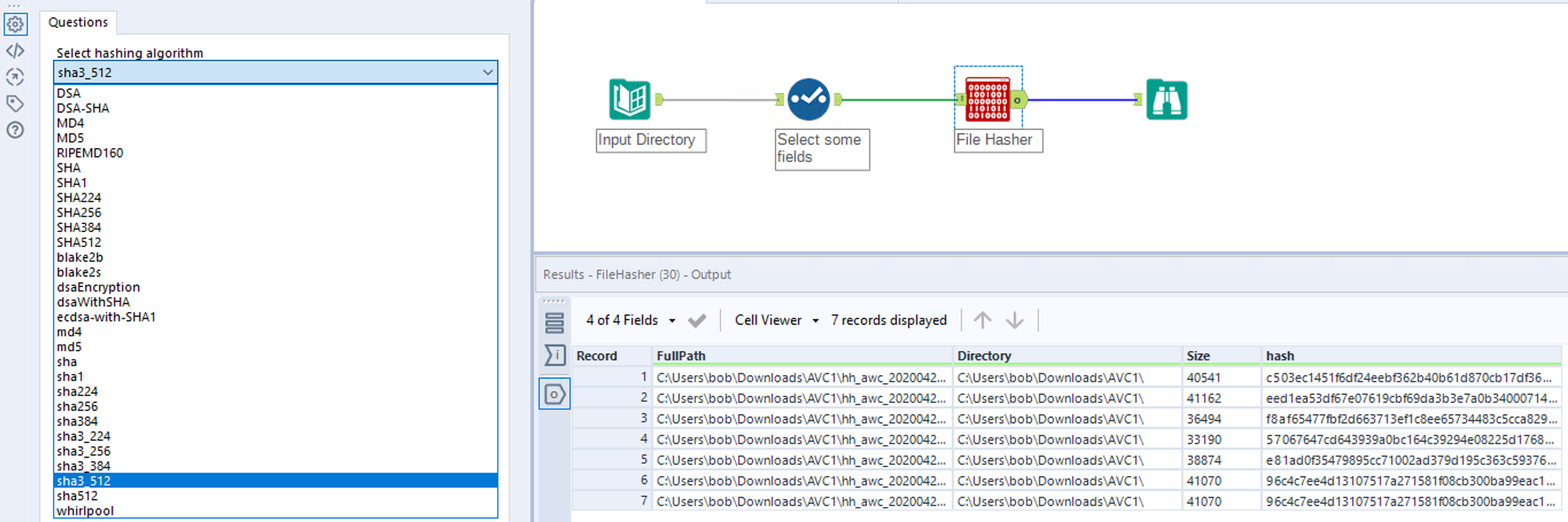
If you want to compare two folders just use two Directory tools, union them and input to the Macro.
The macro is available in the Alteryx Gallery for anyone to download.