
So everyone knows Machine Learning / Artificial Intelligence / Cognitive Computing, call it what you will, is the new marketing catchphrase for people trying to sell their software products and services. You can be sure if it’s not already baked in then it’s in the roadmap for 2020.
It used to be ‘Big Data’, but we got tired of hearing that, so a few control+h presses later and, hey presto, Machine Learning (ML) has arrived.
Don’t get me wrong, I’m convinced ML will have a profound effect in the coming years, but like most technologies, we overestimate the short term effect and underestimate the long term.
As the saying goes, the future is already here — it’s just not very evenly distributed.

I read lots of articles on ML that seem fantastic but it’s hard to get a grasp on something when you haven’t really used it for yourself. I wanted to know if ‘ordinary’ people can use it, and what for? To satisfy my curiosity I decided to see if I could train a neural network to generate product names for clothing based on the product names we are already using in IC Group.
Getting Training Data
Data is the raw material for Neural Networks and the more data the better. If you’re data is already big then great! If not then don’t worry, you can still get interesting results.
To feed the network I extracted the entire history of style names of our three core brands, namely Peak Performance, Tiger of Sweden and By Malene Birger.
After cleaning the data to remove numbers and other ‘junk’ (for example Peak Performance often start style names with the abbreviation ‘JR’ for junior ), the raw data consisted of the following number of style names.
- Peak Performance: 7,590
- Tiger of Sweden: 13,087
- By Malene Birger: 15,419
Not a huge corpus of data to go with but hopefully it should be enough to generate something of interest.
How Does This Thing Work?
The type of Neural Network I used is technically called a Recurrent Neural Network, or RNN for short. It essentially takes training data and ‘learns’ patterns in the data by feeding the data through layers. It also has some ‘memory’ (called LTSM or Long / short term memory!) so that as well as the input to the layer having influence it also selectively remembers or forgets the result of previous iterations.
For text this means you can feed the network large passages of text and the network will ‘learn’ how to write new text without knowing anything about grammar, spelling or punctuation. If you feed it all of Shakespeare’s works and train enough it will generate text that looks like real Shakespeare but is completely new work!
It may sound pretty complicated (and it is) but as a user you don’t really need to know much to get started. There’s ready-to-use scripts everywhere on the internet (Github + Google are your friends) that have full instructions. It’s very much plug and play and took me about an hour to get started from scratch.
I’ve also included links at the bottom of the article pointing to the code I used.
Our Current Product Names (The Training Data)
To give you an idea what types of product names we currently use I selected a few at random to give you a taste. Note that they are all short names (no more than 10 characters) and are not always ‘real’ words or even names.
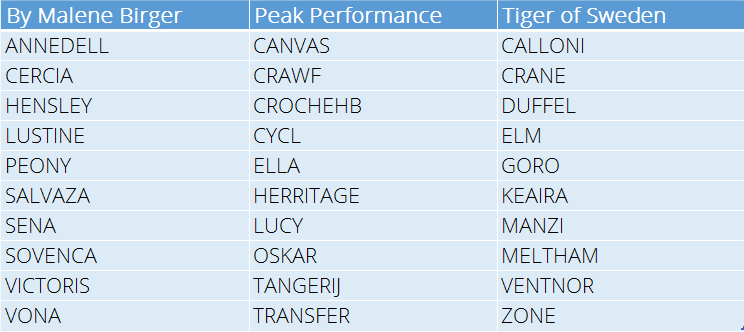
The names tend to have a Brand ‘feel’, so for example By Malene Birger use softer, slightly exotic sounding names to fit their Brand image and target consumer. It will be fun to see if the Neural Network can get this detail right.
Training the Network
This process is surprisingly simple. Just feed the network a text file with all the current names, one file per brand, then run the training script, sit back and get a coffee or three.
Since the training data is fairly small this doesn’t actually take very long (it took me a couple of hours per brand using a virtual machine) but is highly dependent on a handful of parameters that can be set plus the capabilities of your computer. Probably the most important parameters are these:
- Number of layers in the network
- RNN size, this is the number of hidden unit (or nodes) in the network
- Training Epochs, basically how long to train the model for
Basically more layers, more nodes in the layers and longer training gives better results but can take much longer and the benefit isn’t always worth the effort. Trial and error often works just as well!
Does This Thing Really Work?
After training the model we simply use it to generate new names. This is called sampling the model, you can generate samples using some starting text but in my case I just let the model pick a random starting point.
So here’s a sample of the names generated per brand.
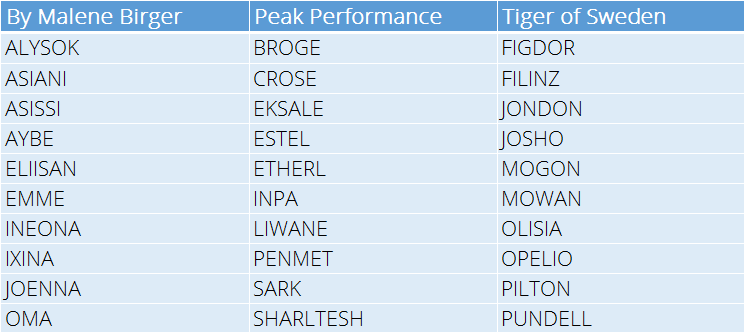
Bearing in mind that the network knows nothing about language I think it did a remarkably good job of capturing the essence of the brands names.
To emphasise once again, the network doesn’t know anything about the constructs of words, what vowels are or anything else for that matter. It learns these patterns purely from the training data and then builds a model to generate new words using the same rules.
The model can be sampled over and over again so there’s an unlimited supply of names.
Can Neural Networks be Creative?
If we really want to play around we can change the parameters of the sampling to try and generate more creative names.
One of these parameters (called temperature) basically tells the network how confident it should be about the name (actually how confident it should be about the next letter in the generated word). If we turn up the temperature the model becomes more aggressive and suggests ‘wilder’ names.
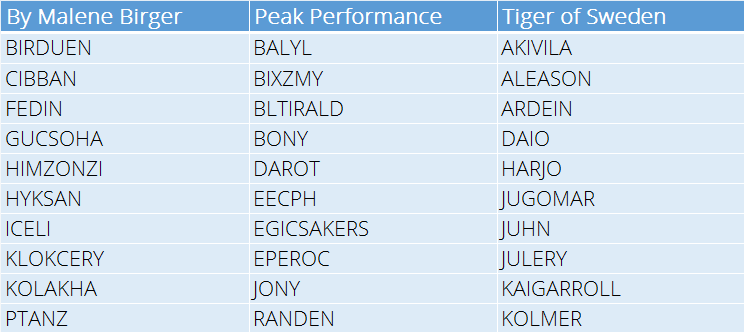
I would definitely buy a blazer from Tiger of Sweden called JUGOMAR or maybe my girlfriend would like a dress from By Malene Birger called CIBBAN or some Peak Performance ski pants called RANDEN.
Of course if we turn up too much on the creativity then it starts to generate some nonsense!
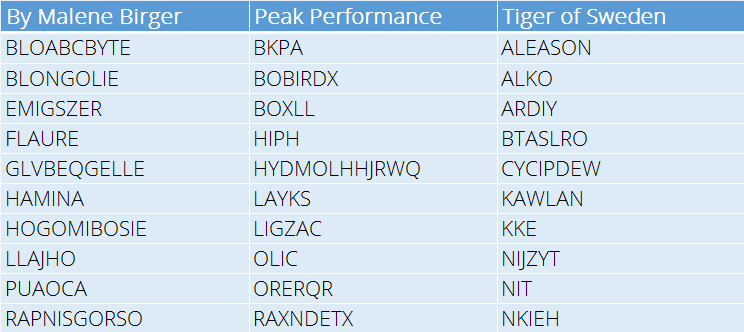
But even in the weirdness we get names like FLAURE, LAYKS and KAWLAN which I think sound like great product names 😃
Summing Up
This was of course all done for fun, but it shows that these types of networks are not impossible to use and someone with decent computer skills can get these up and running in a matter of hours.
If ML really is going to explode in the coming years then they will need to be easier to interact with than they are today. There will never be enough data scientists to satisfy demand, so just like spreadsheet programs made everyone a numbers whizz I expect user interfaces and APIs will be developed so less skilled users can create, train, and deploy ML models into production.
It Almost Makes Sense
As a final challenge I tried making new product descriptions by training the model on current descriptions. It almost makes sense but could maybe do with a bit more training 😉
This is one for Peak Performance!
Stylish Mid feel shortany ski town, it with a shell is a fixent windproof, comfortable, keeping this fit delivers the wicking, breathable Joad.
References If You Feel Inspired To Try Yourself!
If you feel like reading more or even trying for yourself then the code for the RNN is available to download here.
https://github.com/jcjohnson/torch-rnn
And more general reading on generating text using an RNN is here.