Transferring RMB to digital RMB on a smartphone in China
Current ‘Digital’ Money
As much as many people use banking apps and send money via their smartphones, money isn’t really digital yet.
What do I mean by ‘not digital’? Of course it doesn’t mean you need to physically transfer paper money and metal coins to buy a coffee. You can of course do this digitally on your phone.
The digital experience today is mostly a UX layer of digitisation over legacy underlying systems. Think about sending money from your home country to a friend or relative abroad. You open your mobile banking app, enter their bank IBAN number, a few other details along with the amount and currency and that’s it!
Seems great? Not really. Nothing has actually happened apart from you gave an instruction to your bank move an amount X from bank A to bank B. The transaction was really an *instruction* with no guarantee to be carried out in any particular timeframe or even to be carried out at all.
The other major difference to real digital money is that without a bank account tied to your phone you simply can’t transfer money. I can’t send money to a vending machine for example without the machine being owned by a company that runs a bank account on behalf of the machine.
This doesn’t mean that digital money isn’t coming soon. Just recently a major report was released produced by six Central Banks (The Bank of Canada, European Central Bank, Bank of Japan, Sveriges Riksbank, Swiss National Bank, Bank of England, Board of Governors of the Federal Reserve and Bank for International Settlements) that discusses the key requirements of a true digital currency issued by Central Banks.
Just recently PayPal have also announced support for Cryptocurrencies with native support on their platform.
Real Digital Money
What I call real digital money doesn’t need a bank account, it just needs a wallet to store the digital currency. The account number is the wallet address.
Of course this is how cryptocurrencies work using the blockchain, but digital currencies don’t have to use blockchains. They could also be run by a Central Bank and issued or redeemed 1:1 for the national currency. Think of a Euro and a Digital Euro both of equal value but one is way more flexible than the other.
Digital currencies issued by a Central Bank would allow direct payments to be made from Governments to citizens without going through the traditional banking system. This would also make it much easier to include the entire population since only a smartphone would be required, not only those with bank accounts.
When you send money digitally the money is actually transmitted in real time, not just a promise to do so at some point in the future. It’s funny to think that in the year 2020 you can’t settle payments out of banking hours, on weekends or on public holidays 🤯
Money is just ones and zeroes
Money as Data
To my mind one of the biggest advantages is that money can finally be transmitted and processed just like data or any other digital information. This also means it can be programmed and automated and no longer needs to have a separate flow from the rest of you processes.
Your data flow and your payment flow can be combined.
What do I mean by that?
Imagine you have a process where you extract some data for a client, process the data in some way and write the data back to some destination. Classic ETL stuff. Image also that you invoice the customer based on the volume of work done.
The machine to machine economy or M2M will also allow IoT to better fulfil its promise where remote sensors can measure but also make and receive payments.
As it stands today you would make the process for the data and in parallel make some reporting on the process itself so you can send the details to finance every month in order to create an invoice for the service provided.
The analytical process may write some data to a database every second and the payment flow starts by aggregating the data on a monthly basis to see how much work you did last month.
But there’s no reason why in future the process can’t also invoice itself and receive payment itself. It’s just another (or the same) interface into the clients systems, request payment along with an itemised invoice of the work done.
Precessing and Payment occur together
The customers system could validate the invoice versus the work done and make the payment automatically. Testing the payment process would just be another part of the implementation of the ‘normal’ data process.
You have a full audit of the transaction, get payment immediately and avoid involving finance at all after the initial set up. No need to reconcile payments weeks or months after the actual work was done.
Vending machines ordering exact stock levels from vending services in order to be filled up, selecting different suppliers based on most competitive prices.
Your retail POS could order and make payment on new stock when stock levels drop below a predetermined levels.
A delivery drone could pay a number of last mile delivery drones based on best price / speed / payload size etc.
Cars could invoice you based on the actual distance driven so car leasing agreements could work more like care sharing apps
Your laptop / phone could connect to WiFi routers around it and pay for Internet access. If paid by byte then it could automatically connect to multiple providers at the same time to improve speed.
APIs that you use today but are billed by subscription every month or year could be truly pay as you use with billing an integral part of the API
While other areas of tech have raced ahead money is still very much stuck in the 1970’s. Yes we have nice apps and user interfaces but the fundamentals underneath all this are largely unchanged. This will inevitably change in the coming years and digital currencies will play a large part in this.
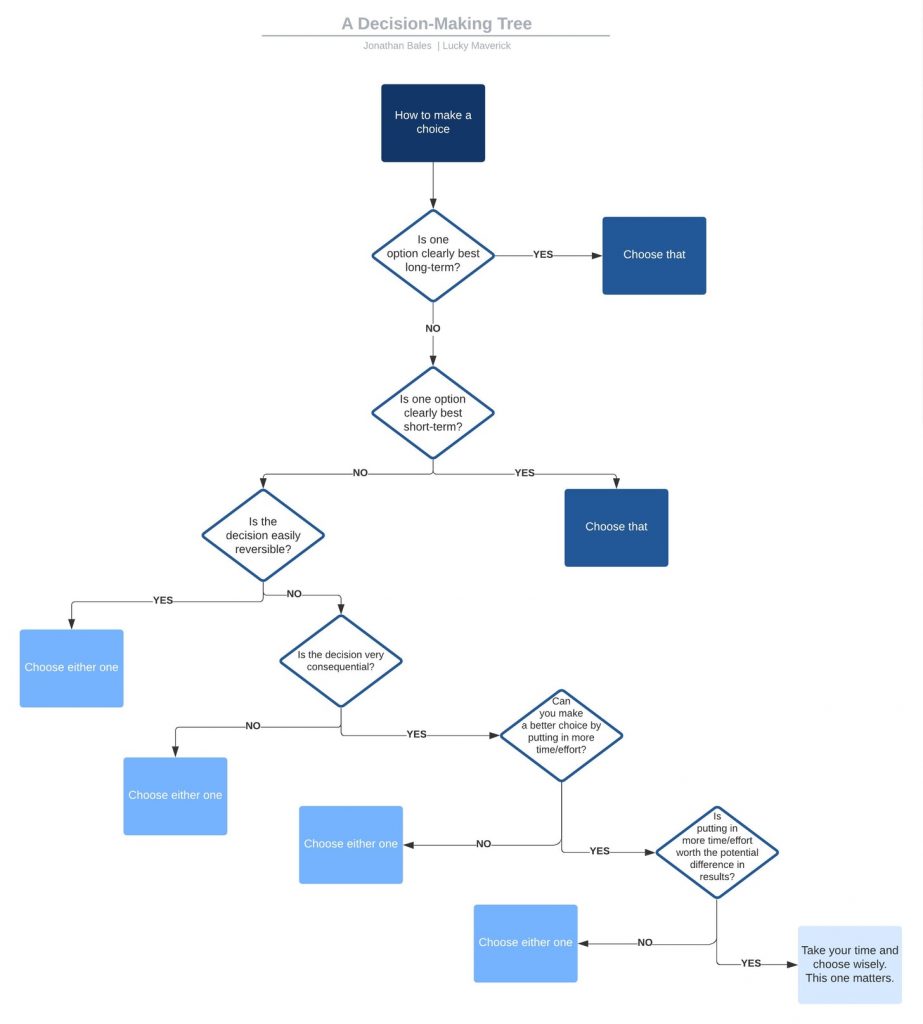
For those that like a nice process for making decisions here’s a Decision-Making Tree.
Decision-Making Tree
It may seem lighthearted but most decisions are not actually that important. Most of the time it’s probably better just to choose a path and move forward. If it’s wrong but trivial to fix later why bother delaying over the choice?
“Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions. But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.”
The tool uses the standard Python libraries and installs to the File System tab.
File Deter tool on the Alteryx File System tab
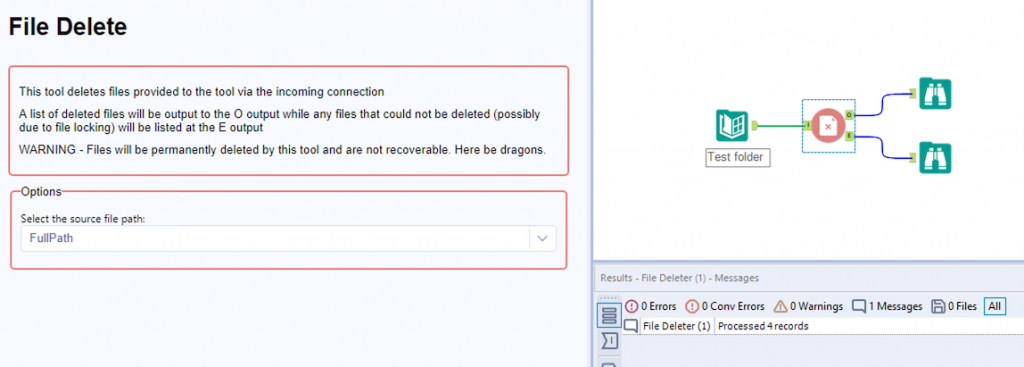
This tool accepts a single input. The tool should be mapped to the full path of the files to delete, usually provided by placing a Directory tool before this tool.
WARNING Files deleted using this tool will be permanently deleted and are not recoverable. Use with care. You have been warned.
Successful operations will be output to the O-Output. If the file could not be deleted (most likely due to file locking issues) the output will be sent to the E-Output along with the error reason.
Saving credentials for use in an Alteryx workflow is a very common use case. Maybe you use an API and need to save Client keys or secrets and getting these credentials into a workflow without hard coding is tricky.
It’s common to either read from a text file located in a protected location or use an Environment variable to save them. Not ideal especially when there’s a better solution.
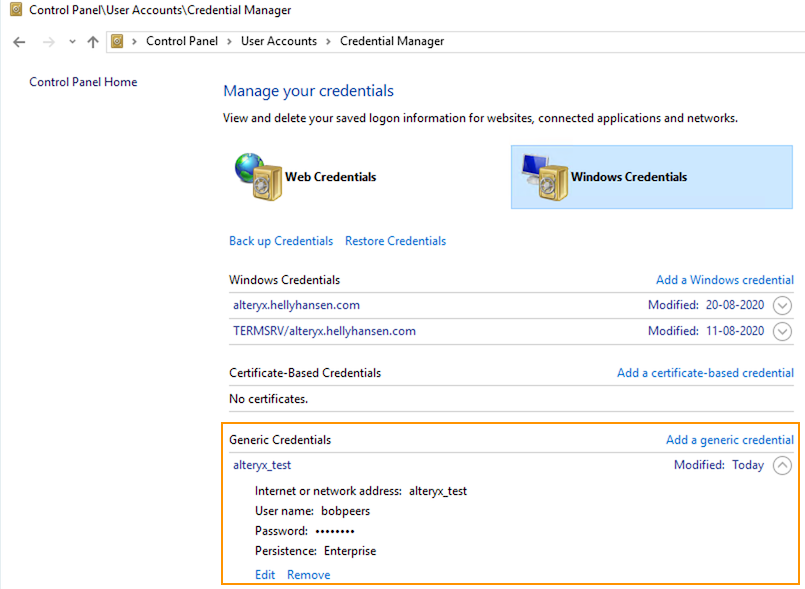
Windows has a built-in credentials manager called, not surprisingly, Windows Credential Manager but Alteryx has no native way of accessing saved credentials from here.
The Solution
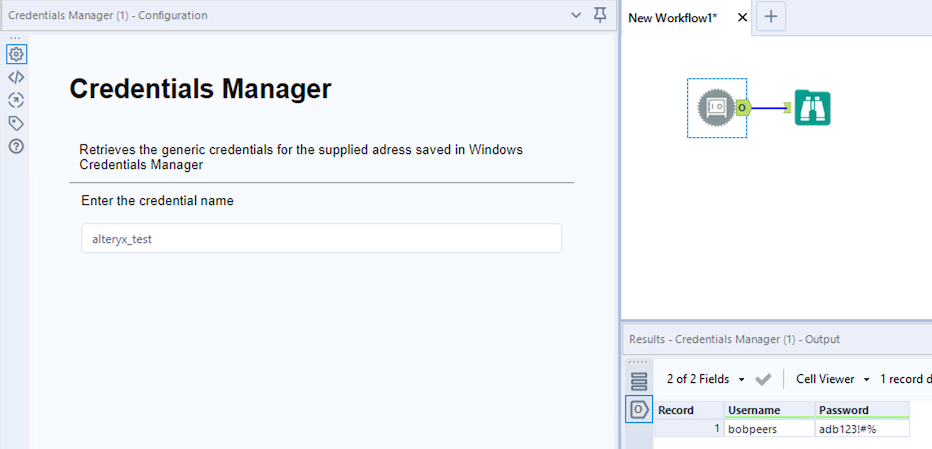
To solve this issue I’ve created a custom Alteryx tool using the Python SDK that allows you to read saved credentials at runtime into the workflow. The tool simply accepts the credentials name to retrieve and returns the user name and password.
Example workflow using Credential Tool
The credentials need to be saved in the Generic section of Credential Manager.
As a consultant you get to work with many different systems, some easy, some difficult and some downright weird.
Magento Commerce fits firmly into the last category.
For those that don’t know Magento is a very popular E-commerce platform owned by Adobe and used by some of the largest companies in the world.
How APIs Normally Work
When using APIs it’s standard practice to use pagination to avoid retrieving too many records at once and potentially maxing out the memory resources of either the server or your client.
Pagination is requesting records in batches and then selecting the first ‘page’ of data followed by the next and so on until all the data is downloaded.
Their Commerce API is well documented and at first look seems pretty standard.
Magento uses a fairly standard syntax to request pages, this requests 1000 records per batch and the first page of results.
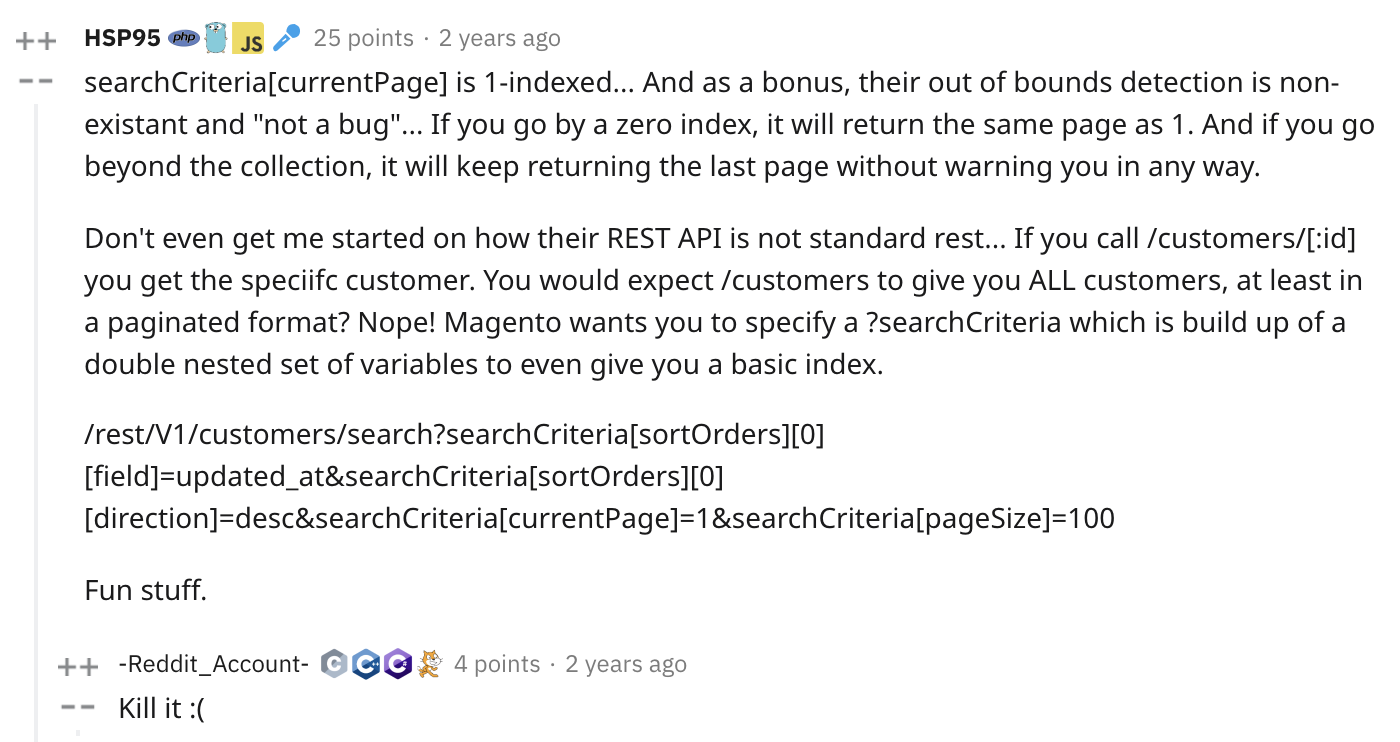
Normally the return message would include a link to the next page, not Magento.
Normally if you request a page beyond the end of the dataset you’ll get no data,
Magento just returns the last items over and over again.
To find out if I’ve reached the end of the dataset I ended up reading the response, removing the page number, then hashing the contents and comparing to the hash of the previous returned page. If they’re the same I’m getting the same data again so I can stop 🙄
try:
# get next page
URL = base_URL.replace('[currentPage]=1', f'[currentPage]={i}')
r = requests.get(URL, auth=headeroauth)
# remove page number and hash contents
hash = gethash(r.text.replace(f'"current_page":{i}','').encode('utf-8'))
if hash == last_hash:
# I'm at the end
break
else:
last_hash = hash
print(URL)
with open(f'{download_dir}customer_page{i}.json', 'w') as f:
f.write(r.text)
except Exception as e:
print(str(e))
This works most of the time except in the circumstance where the underlying data changes between the two ‘final’ calls so I get the same data set again but with a few ‘extra’ records. Because of thisI I still have to check for duplicates before loading the data into a database.
While Googling for the issue I was pleased to find that Reddit tends to agree with my sentiments 😁
You can install by downloading the yxi file under the releases tab in GitHub and simply double click to install. The tools will be available in the Alteryx Tool menus and function just like the built-in tools that ship with Alteryx.
Copies or moves files from source to destination. If the destination is a path the filenames will be unchanged, otherwise it will use the provided filename.
Takes the incoming mapped file path and extracts the contained files into the supplied location. By default it will not overwrite existing files but this can be changed in the tools configuration.
Imagine you have a folder full of files, all with different names, where you need to identify which, if any, are duplicates.
Some of these might be the same?
You could use the file size but it’s not a guarantee the files are exactly the same just because they are the same size.
Hashing files is an easy way to identify if two files are the same as each other since even small changes in the file contents will result in a completely different hash. It also works on the file itself so the filename is irrelevant.
Current Alteryx Options
Alteryx has an md5 formula but that can only be used to calculate the hash of a field not an entire file.
The current solution is to read the file as a Blob using the blob Input tool then create an md5 hash of the blob field. While this works fine it’s very slow and you can only use md5 as the hashing algorithm.
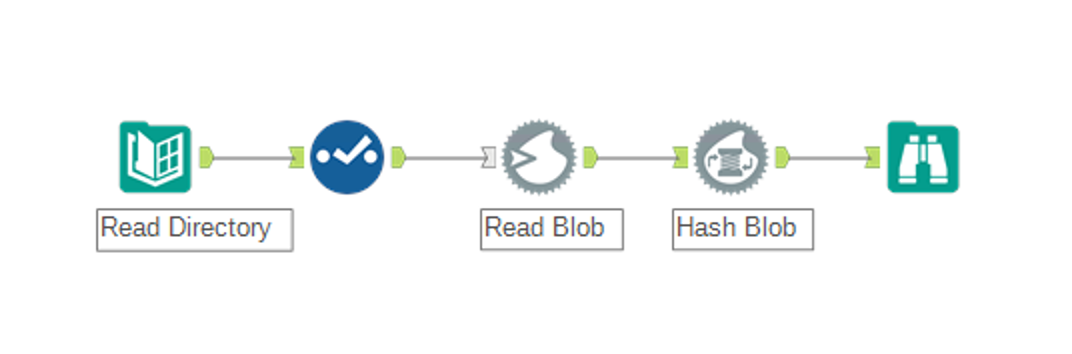
Python Macro Solution
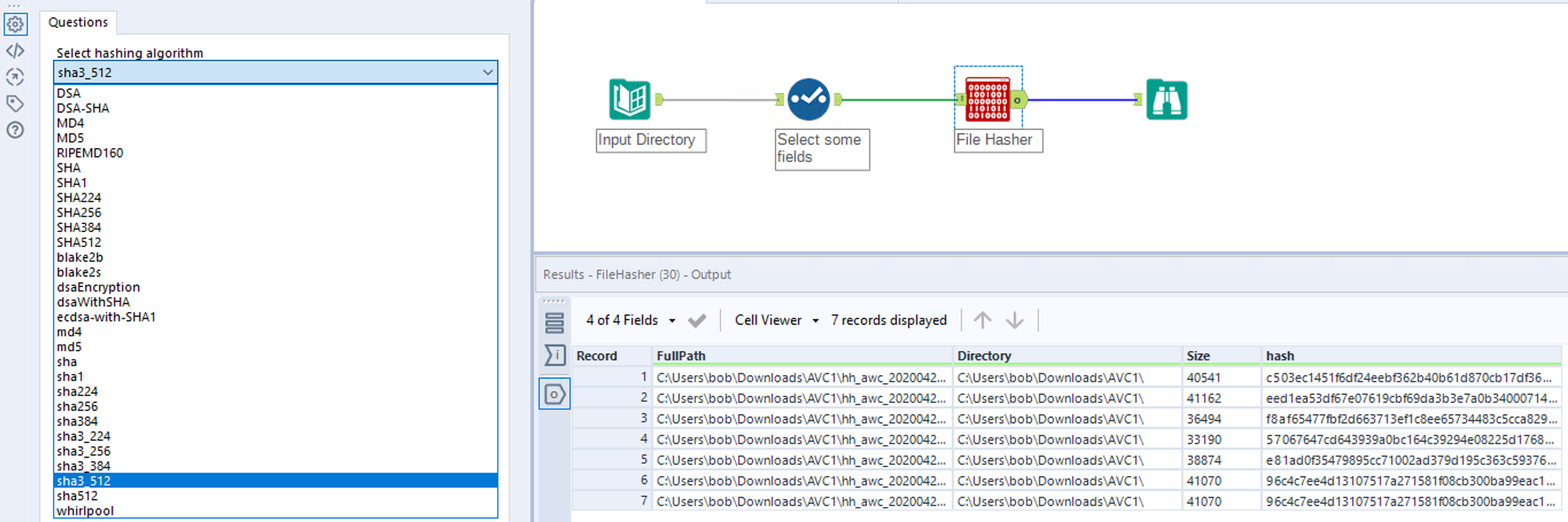
To give more options and flexibility I’ve created a macros based on the python tool. The macros uses python’s hashlib library to do the hashing as this allows for 29 different hashing algorithms made available through the OpenSSL library.
Using the macro is simple, just feed data to the macro where one field contains the full path to the file to hash and select the hashing algorithm to use. The macro will hash the file and return all the input data while appending the hash field to the end.
File type is also irrelevant. It works equally on executables, images, binary files and so on.
If you want to compare two folders just use two Directory tools, union them and input to the Macro.
The macro is available in the Alteryx Gallery for anyone to download.
As much as bitcoin (note here I’m talking about the software also known as bitcoin core) is a highly complex system many of the basic elements can be fairly easily described and demonstrated.
Here I’ll demonstrate a very simple example using python showing how mining works and how something called ‘difficulty’ is controlled.
But first we need some background.
Mining (New Blocks)
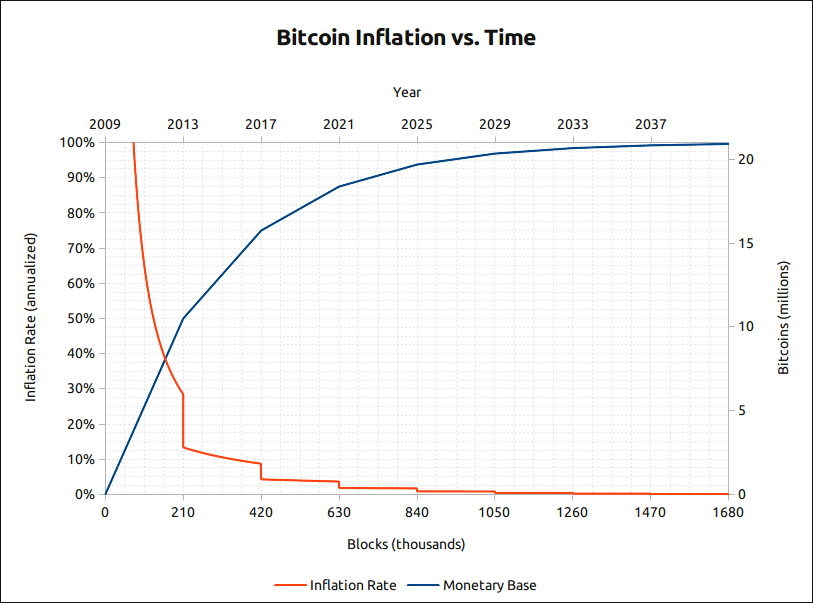
One of the most important elements is the process of mining that in turn adds new blocks to the blockchain but also creates newly minted Bitcoin.
Mining is where computers basically race each other to solve a mathematical problem. If they solve it first they create a new block of transactions on the blockchain and are rewarded with newly minted Bitcoins.
What is the Block Reward? The amount that miners may claim as a reward for creating a block.
These new Bitcoins are known as the Block Reward which coincidently is big news right now as this reward is due to be cut in half on May 12th. This event, known as the Halving, occurs every 210000 blocks which translates to every 4 years or so.
But back to the miners.
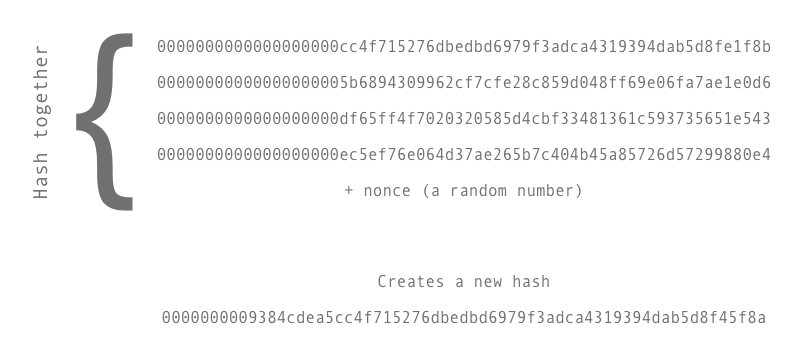
The problem they need to solve is actually simple to explain but hard to solve. They take a group of transaction hashes and hash them together along with a random variable (called a nonce). This is shown below.
The trick is that the Bitcoin software controls the difficulty by telling the miners that the hash they need to produce must start with at least a minimum number of zeros (target hash).
Since the hashes generated are completely random the only way to generate a hash with the required number of zeros is to keep adding different random number to the original hash and try again.
What is Hashing?
In simple terms, hashing means taking an input string of any length and giving out an output of a fixed length. In the context of cryptocurrencies like bitcoin, the transactions are taken as input and run through a hashing algorithm (bitcoin uses SHA-256) which gives an output of a fixed length.
The magic of hashing is that it’s a one way process and output cannot be predicted from the input, meaning brute force computing is the only way to get the required output hash. There are no shortcuts.
The other benefit of hashing is that although they are hard to generate they can be very easily verified afterwards using almost no computing power. So my laptop can verify a miner has created a valid block with a valid hash in microseconds.
Hashing is a type of Trapdoor function since it is easy to go from input to hash but impossible to get the original input from the hash.
How does the difficulty adjust over time?
Bitcoin is programmed to generate new blocks every 10 minutes on average. A predictable supply.
In the early days the computing power used for mining was minimal so the difficulty to produce a block was relatively easy and only a few zeros were required for a valid block.
As the years have passed more and more miners come onboard with more and more powerful equipment. If the difficulty didn’t adjust new blocks would be created too fast and the average block time would be far below 10 minutes.
This would also mean the total supply (capped at 21 million bitcoin) would be minted almost immediately.
The elegance of mining and difficulty retargeting is that every 2016 blocks (about every 2 weeks) the code self adjusts the difficulty so if blocks are being mined too fast the difficulty increases, meaning miners now have to calculate hashes with more leading zeroes.
Conversely if mining power leaves the network the opposite happens. Blocks are mined too slowly so after 2016 blocks the difficulty is adjusted downwards and fewer leading zeros are required on hashes.
OK, I Need a Demonstration 🤯
To demonstrate the mining process we can use some fairly simple python code.
This code runs 6 loops with increasing difficulty starting with a target hash with no zeros and ending with 5. Within each difficulty it calculates a hash that matches the target hash and outputs the number of iterations required, the time taken and the hash produced.
The initial input is a text string, in this case ‘Hash try #’.
Next it creates a hash of the text and checks if the hash has the required number of leading zeros. If it does we print the output and hash and then try again but on the next loop the required zeros (target hash) increased by one.
If the hash doesn’t meet our difficulty we add a digit to the input text, hash this and test again. This loop continues until we finally get an output hash that meets our target hash.
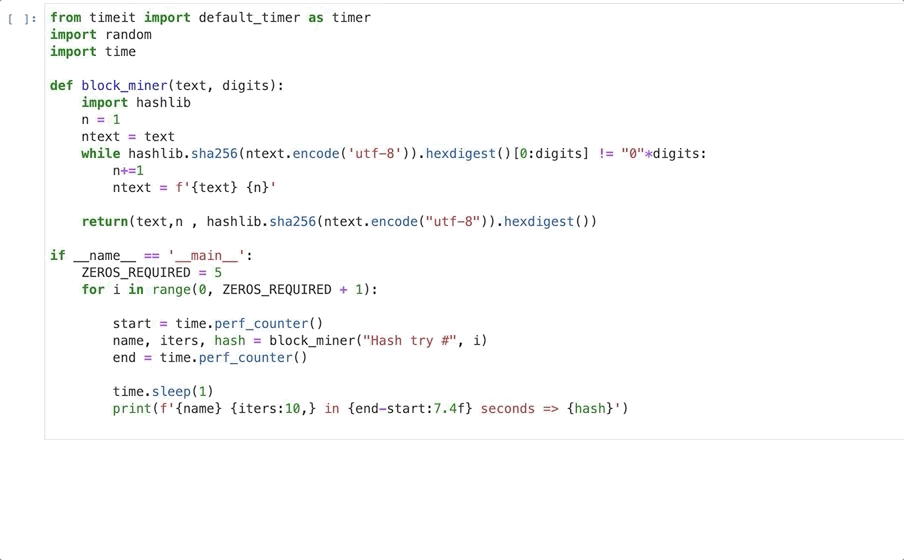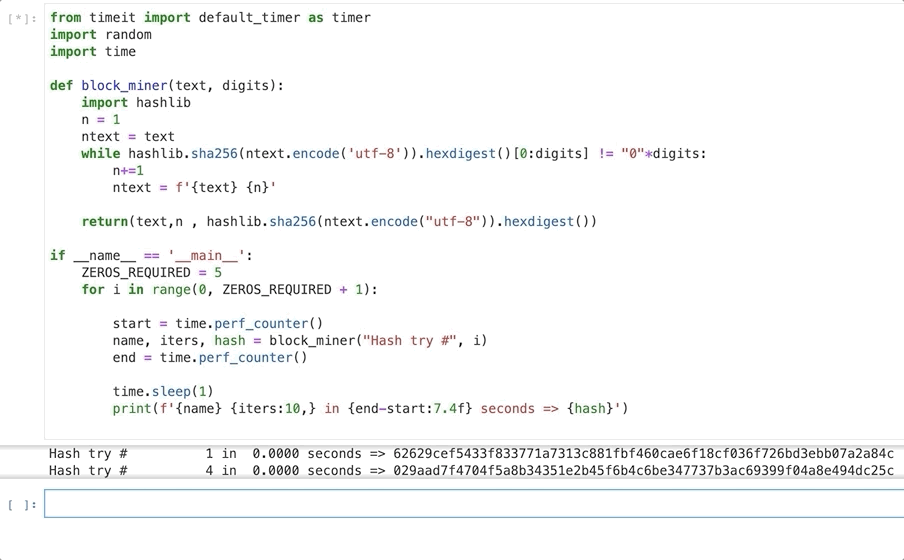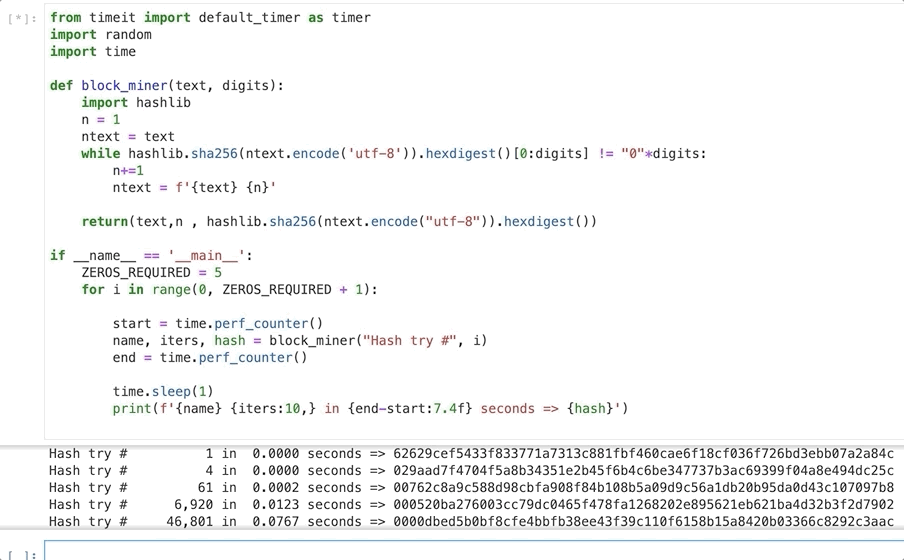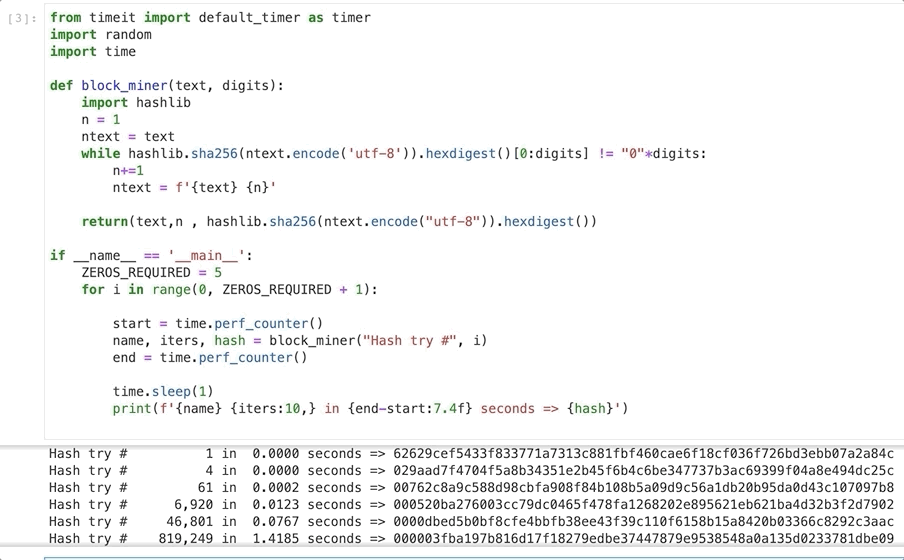
Difficulty Increases Rapidly!!
As you can see creating a hash with one leading zero is trivially easy even on my laptop. Even three leading zeros only takes 0.012 seconds.
But things really change rapidly as we increase the difficulty so at 5 leading zeros it takes 1.45 seconds and over 800.000 iterations.
On my Macbook Pro generating a hash with 6 leading zeros took 64 seconds and over 44 million iterations.
I finally tried to generate a hash with 7 leading zeros:
Hash try # 675,193,594 in 952.3370 seconds => 000000096a22c89e6d0a2f1ea37719f8546aac9becfaf1e7875983f6df35adfa
After 675 million iterations and almost 16 minutes the target hash was found!
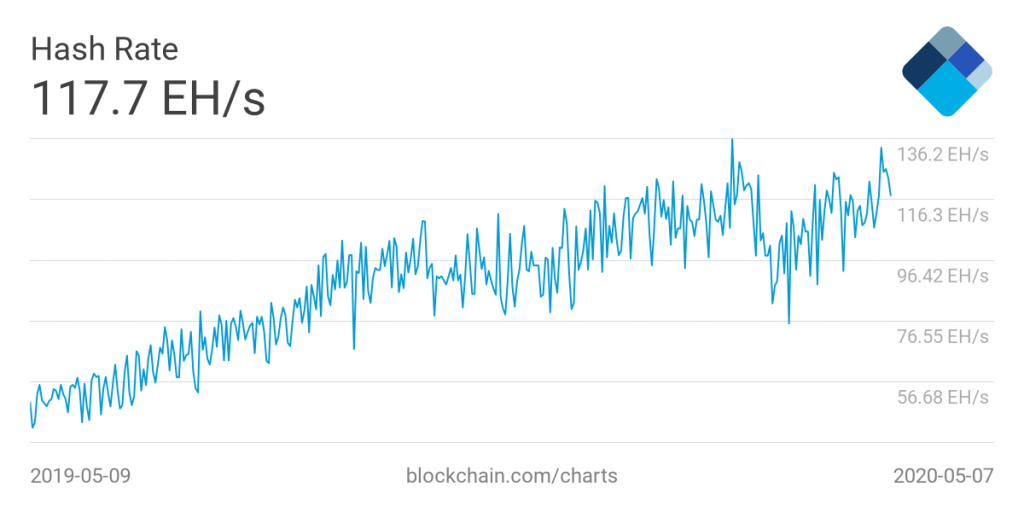
The current difficulty as of today requires 19 leading zeros and miners calculate 117 Exahashes per second (one Exahash is 1.000.000.000.000.000.000 or a million million million)
Historical Bitcoin Hash Rate in Exa hashes (1018) per second
This explains why mining on regular computers is no longer possible and dedicated hardware is required located in places where electricity is cheap.
The Code
If you just copy this code and run you can try for yourself. Try adjusting the variable ZEROS_REQUIRED to another integer to change the hash target.
You can also try with a different input text by editing “Hash try #” and changing it to any text you like.
from timeit import default_timer as timer
import random
import time
def block_miner(text, digits):
import hashlib
n = 1
ntext = text
while hashlib.sha256(ntext.encode('utf-8')).hexdigest()[0:digits] != "0"*digits:
n+=1
ntext = f'{text} {n}'
return(text,n , hashlib.sha256(ntext.encode("utf-8")).hexdigest())
if __name__ == '__main__':
ZEROS_REQUIRED = 6
for i in range(0, ZEROS_REQUIRED + 1):
start = time.perf_counter()
name, iters, hash = block_miner("Hash try #", i)
end = time.perf_counter()
print(f'{name} {iters:10,} in {end-start:7.4f} seconds => {hash}')
One of the amazing aspects of bitcoin is that everything is controlled algorithmically and can be independently validated by anyone. If you run a bitcoin node you can see every transactions and validate them for yourself if you wish.
There’s been a clear trend going on for many years now known as ‘No code’ or ‘Low code’.
This essentially describes tools or platforms that provide you with a GUI that abstracts away the underlying technicalities so non-technical users can use powerful software.
Doing this has been a huge benefit to business since the addressable market for Excel-like tools is 1000x greater than Coding-like tools. Business users benefit as well since they effectively leverage their skills and become a more valuable employee.
So Why Learn to Code?
It’s simple. When we talk about No Code or Low Code it just means that someone else has written the underlying code and abstracted the problem into a more easily understandable form. This usually ends up in the form of a component, tool or function you can use in the platform.
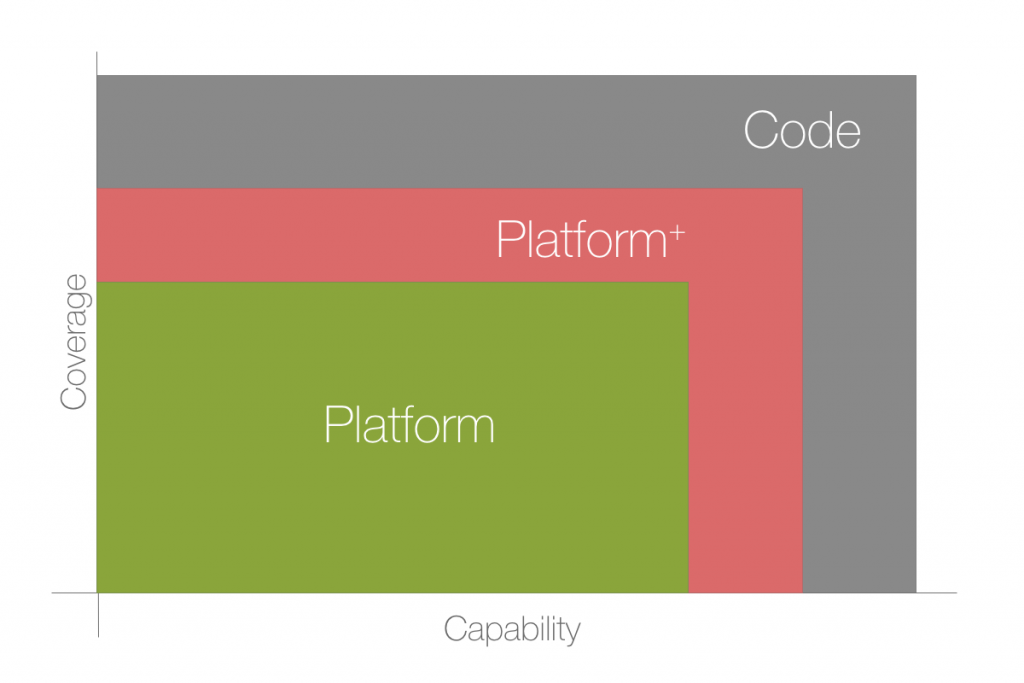
This is great for maybe 70-80% of use cases. It’s fast to develop, simple to use and has a quick learning curve using pre-built components.
However as you become more experienced you’ll discover the more problems you encounter the greater the chance that your particular use case has not been covered.
The solution tends to be adding complexity while trying to work within the constraints of your particular tool. Which in turn defeats the object of using the tool in the first place, since the whole idea is they are easy to use and understand.
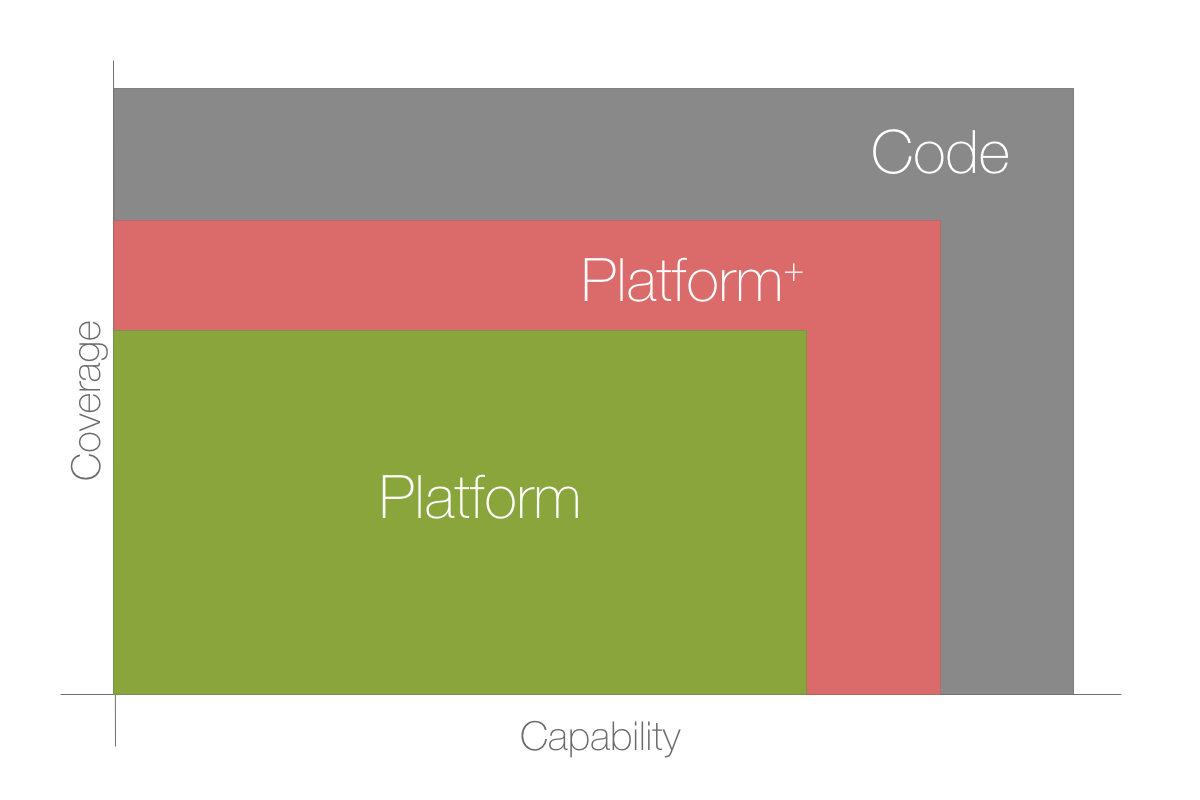
This leads to the red area in the chart shown here, the part I called Platform+. This is a dangerous area as you’re pushing the limits of what your tool can do while making the solution overly complex.
Platform - safe
Platform+ - might want to rethink
Code - just code it
But how do you know when you’re ventured into the red area? A few pointers.
An colleague experienced in your tool of choice can’t understand what you’ve done in 10 minutes
You rely on a patchwork of external tools, batch files, scripts, other executables linked together
Linked dependencies and applications become a spaghetti like construction
You end up using brute force on problems (parsing html and xml like it’s a string…)
Your solution is hard to update
You think the solution should be easy but it proves very difficult to achieve
For me the last point is probably the most telling sign. If I know how to solve the problem from an architectural point of view but find it really hard to actually create the solution then it’s a warning flag in my head..
The Happy Medium
You should use no or low code tools as much as possible. Development time is reduced considerably and ease of use means they are a huge benefit.
Having aid that I do think it’s important to recognize the limits of whatever tools you’re using and consider if it’s really the best solution or just the best solution you’re able to make with this tool.
Knowing how to code effectively gives you superpowers and increases the surface area of possible solutions.
Consider coding to be like an extended toolbox, you don’t always need to open the big toolbox but it’s great to know if you do you’ll always find the tool you need to fix the problem.